

When making performance improvements in your database SQL Index Usage is one of the most valuable and essential features. SQL Indexes are used to retrieve data from databases by reducing the workload.
Indexes are great options to improve query performance. Use indexes smartly without misusing them everywhere. Here I try to highlight how to use an index to improve the query performance.
SQL tuning is involved in executing queries with a minimum workload. Minimum workload refers to a query that can be executed efficiently by reducing resource consumption. You can analyze the resource usage by execution plan. Below are examples of how indexes change execution plans.
1. Commonly no one needs all data in a single query. Most probably it’s a small bunch of data filtered by query and filtering is easy by adding an index into a table that will reduce the resource usage.
2. If your table contains over 100,000 records and you have a query with an ORDER BY clause. If the ORDER BY clause satisfies the index, then Oracle does not want to scan the full table to retrieve the dataset. It filters datasets by index.
1. SQL Index Usage in a Single Table
If you have query selecting values using a specific column, then you can add an index into a column that will improve performance.
Query-1
-- SELECT * FROM Employee WHERE Employee_Name = 'Enni'; --

But Index performance will be low if you are fetching less than 10% of rows by a query. Therefore, select the best column for the index because the index may not perform everywhere. See below example
Query-2
-- SELECT * FROM Employee WHERE JOB_TITLE='Software Engineer' --
2. Bypass the Query Optimizer JOIN tables
Query optimizer evaluates the explain plan when running the query. let’s create a simple JOIN example with Employee and Department tables by using the column Dep_Id. Also, Dep_Id is the primary key of DEPARTMENT and therefore creates a unique index for Dep_Id.
Query-3
-- SELECT e.NAME, d.DEPARTMENT_NAME FROM Employee e, Department d WHERE e.DEPARTMENT_ID = d.DEP_ID AND e.JOB_TITLE = 'Software Engineer'; --

In the above scenario, there are Indexes on the Employee table as DEPARTMENT_ID and JOB_TITLE then the Query optimizer create two different explain plans according to the below. Once evaluated both explain plans then select the least cost expensive plan once executing the query.
- DEPARTMENT as an inner table
- EMPLOYEE as an inner table
So far So good and Query optimizer will select best. Now let’s think about you don’t have an index as DEPARTMENT_ID in the Employee table and only available Dep_Id in the DEPARTMENT table. It default creates a unique index because of its primary key on DEPARTMENT. Consider if you have 10 Departments and 10000 Employees in each table.
But if you think the optimizer not doing a great job, maybe that can happen, and you think you want to use EMPLOYEE as the inner table every time. Then you can force the optimizer to use Employee as the inner table by giving HINT to the optimizer. Then HINT will arrange to explain plan according to the order of tables in FROM clause in the query.
Query-4
-- SELECT /*+ordered*/ e.NAME, d.DEPARTMENT_NAME FROM Employee e, Department d WHERE e.DEPARTMENT_ID = d.DEP_ID# AND e.JOB_TITLE = 'Software Engineer' --

Once you apply a HINT then you need to realize Hint will work as you wish BUT over the period data load increases and the statistics change with tables accordingly. Still, you have a hint, and performance may be bad due to HINT. Therefore, keep in mind once you add a HINT optimizer will not guarantee the best plan. It’s up to you to decide the best plan.
If you wish the problem, can raise in future still you have a solution for that. You can arrange the table according to the smallest effective rows in the table to the highest effective rows in the table. Let’s try to evaluate two tables in both orders. Consider now we have 10 departments and 10000 employees with the below queries.
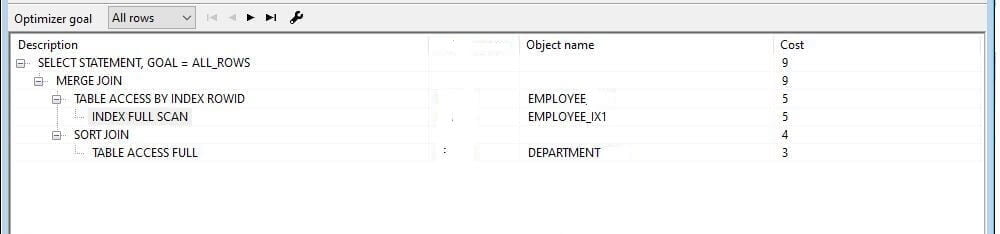
1 Use ORDERED hint and the Employee is the first table in FROM clause (FROM Employee, Department)
Query-5
-- SELECT /*+ordered*/ e.Employee_Name, d.DEPARTMENT_NAME FROM Employee e, Department d /* Employee in first*/ WHERE e.DEPARTMENT_ID = d.DEP_ID; --
2 Use ORDERED hint and the Department is the first table in the FROM clause (FROM Department, Employee)
Query-6
-- SELECT /*+ordered*/ e.Employee_Name, d.DEPARTMENT_NAME FROM Department d, Employee e /* Department is first*/ WHERE e.DEPARTMENT_ID = d.DEP_ID; --
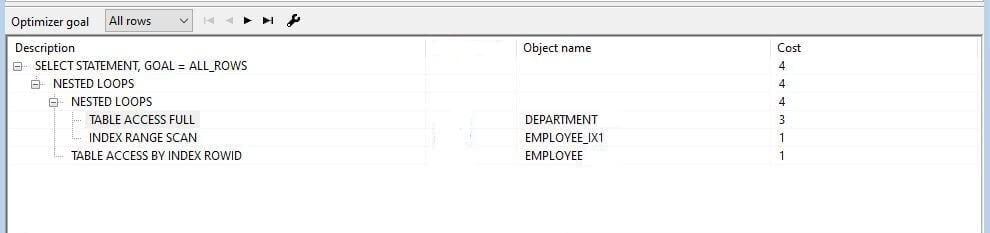
Now we have added Hint (Ordered) and Employee in the First place in FROM clause. Then Employee has 10000 qualified rows in the Employee table. Then the query traverses once from the employee table but accesses 10000 in times DEPARTMENT table. If DEPARTMENT is in first place in FROM clause there is one traverse for DEPARTMENT and 10 times in the Employee table. So, 2nd option performs well. If you use HINTs as a Rule, you can place fewer affective rows in the table first and so on.
If I run the query below without HINTs, then the optimizer selects the least-cost plan
Query-7
-- SELECT e.Employee_Name, d.DEPARTMENT_NAME /* No hints*/ FROM Employee e, Department d /* Employee in first*/ WHERE e.DEPARTMENT_ID = d.DEP_ID; --
Here do not confuse or mix your thinking with opposite table row count. As an example let me explain “query traverse once from employee table but access 10000 times DEPARTMENT table” If an employee is available 30 records scan the employee table once but each and every record has to access the department table. Cost may increase with accessing other table counts.
3. Use untransformed column value
This is an important tip once you are querying for a result set. Usually, we merge tables by WHERE clause, but we need to motivate the optimizer to pick primary or foreign key indexes once join the tables and then execute the query.
If you have a lot of SQL inbuilt functions in the WHERE clause when joining, then the optimizer ignores the use of index unless you have a function base index for them. The below example has multiple SQL functions that are not good for performance.
Query-8
-- SELECT e.Employee_Name, d.DEPARTMENT_NAME FROM Employee e,Department d WHERE TO_NUMBER (NVL(e. DEPARTMENT_ID, 1)) = TO_NUMBER (NVL(d. DEP_ID, 1)) --
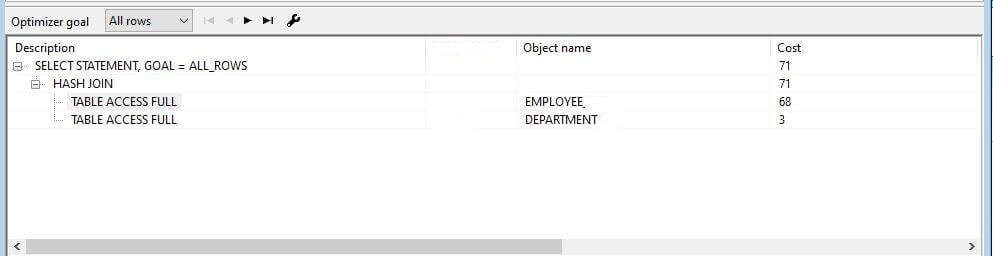
Try to avoid this type of situation use direct column values instead of transformed column values in the WHERE clause. That will improve the performance so write a query as follows if possible WHERE e. DEPARTMENT_ID= d. DEP_ID
The complex expression you may need to avoid. Because these functions affect with explain plan
- NVL(Dep_Id, -1)= ….
- TO_DATE(date_)= ….
- TO_NUMBER( num_) =…
4. Focus SQL on Specific tasks by each segment
SQL is a functional language. You can do a lot of things in a single statement or function. But that will not give optimal performance output. Therefore, write a separate statement for each task rather than doing it in a single code by passing parameters.
But in case you really need to write a complex query then use UNION ALL to concatenate everything into a single unit. UNION ALL brake complex queries into simple blocks of code and also that will improve the performance as well.
See the example code below. Here looking to filter Employees from the “Account” department and join dates between some periods. Consider we have two tasks but going to fulfill in one query.
- Want All Employees from the Account
- Want All Software Employees Who Work in the Account Department and join this year.
In This case, we introduce two new parameters min_date and max_date. in our first requirement parameters will assign ‘All’ for both but in the second requirement start date and end date will be assigned dates of the year. This will work pretty well but if there is an index for join_date do you think the index going to perform?
Query-9
-- SELECT e.Employee_Name, d.DEPARTMENT_NAME FROM Employee e, Department d WHERE e.DEPARTMENT_ID = d.DEP_ID AND e.join_date BETWEEN DECODE(:min_date, 'All', e.join_date, :min_date) AND DECODE(:max_date, 'All', e.join_date, :max_date) AND d.DEPARTMENT_NAME='Account' --
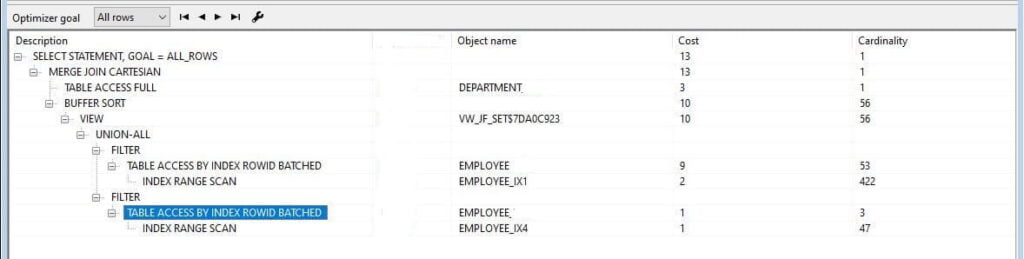
Now here difficult to use the index for filtering column join_date because of join_date use on both sides of between. Let’s try to use UNION ALL for this and break them into small parts.
-- SELECT e.Employee_Name, d.DEPARTMENT_NAME FROM Employee e, Department d WHERE e.DEPARTMENT_ID = d.DEP_ID AND e. join_date BETWEEN :min_date and :max_date And (:min_date !='All' and :max_date!='All') AND d.DEPARTMENT_NAME='Account' AND d.JOT_TITLE='SE' UNION ALL SELECT e.Employee_Name, d.DEPARTMENT_NAME FROM Employee e, Department d WHERE e.DEPARTMENT_ID = d.DEP_ID And (:min_date ='All' or :max_date ='All') AND d.DEPARTMENT_NAME='Account' --
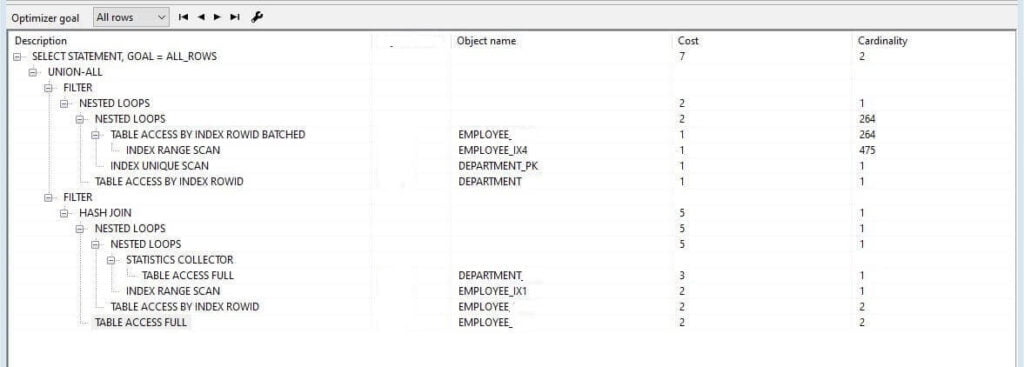
Now try to run explain plan for both queries big set of data then you realize different performances. It’s due to how we separate the tasks due to requirements.
Summary
Indexes are one of the key features in databases to improve the performance of queries. But realize where to use them and use them in an optimum way. Otherwise, indexes can be a headache in your query.
data load is critical for your query performance therefore if you add an index once a time it does not assure the query performer every day until the query is available. performance never ends do it gradually.
