

Performance improvement is not a stick into theory. It’s the same with EXISTS vs IN keywords. It’s practical. In certain cases, EXISTS does well for subqueries rather than IN. In general, if a selective predicate is in the subquery and returning few records, then the IN clause performs well. If selective predicates are in the parent query and return large data records from the subquery, then use EXISTS.
I would like to remind you how IN and EXISTS (exists vs in) keywords run on the database. IN keyword scan all the possible matches in the subquery and EXISTS keyword return as soon as on matching item found. It’s because of EXISTS keyword returns Boolean rather than dataset.
Note: IN clause not considering NULL values when matching but EXISTS match values including NULL values in the database.
Here I use the Oracle database for adding data and retrieve explain plans to explain the examples.
I can summarize this for busy programmers like below and will explain how these two clauses behave in real environments with examples. The recommendations are:
- If most filtering predicates are in a subquery, use IN.
- If most filtering predicates are in the main query, use EXISTS.
In other words,
- IN keyword suit for a large set of records returned by an outer query and small data records returned by an inner query.
- EXISTS for small data records returned by an outer query and big data records returned by the inner query.
First needs to focus on whether explain plan is generated using rule base optimizer or cost base optimizer. if your database setup for cost base optimizing Oracle optimizer creates the same or unique execution plan for IN vs EXISTS, therefore no considerable difference in query performance. I hope to describe the following two ways of building explain plans later in this article.
- Rule Base Oracle optimizer
- Cost Base Oracle optimizer
Rule Base Oracle optimizer
Here I’m going to explain below two cases with examples. Therefore, I need the following dataset and I try to explain the benefits of EXISTS and IN according to the selective predicate.
Case 1 Selective Predicate in the Subquery (Use IN)
Case 2 Selective Filter in the Parent Query (Use EXISTS)
Tables: Employee, Purchase_Orders, Customer
Unique index: employee_id(Employee)
Index On: department_id(Employee), job_title(Employee), Customer_id(Purchase_Orders)
Dataset: The Employee table available 10000 data, Purchase_Orders table has 100000 data
Use IN – Selective Predicate in the Subquery
In this example going to explain once if selective predicate in the subquery. Then how to take benefit of IN clause but first have a look when the use of EXISTS. Query filter all the employees make orders on behalf of customer_id equals with 99 (QUERY-1)
Query-1
--
SELECT e.*
FROM employee e
WHERE EXISTS (SELECT 1 FROM purchase_orders p
WHERE e.employee_id = p.person_id
AND P.customer_id = 99) /* Selective Predicate customer_id=99*/
--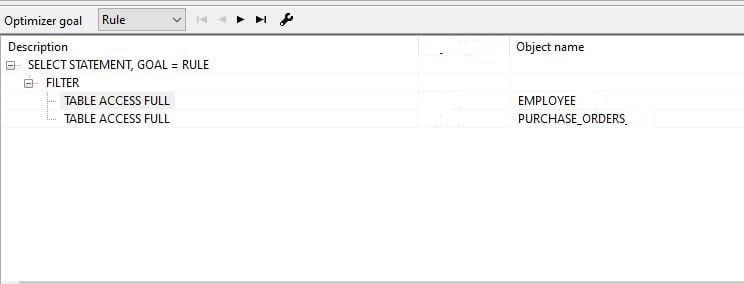
The above query generates the following explain plan and according to the plan, the Employee needs a full table scan. also, there is a purchase_order table scan by index range. What does this mean? Employee have to scan all the rows and each employee row checks against the purchase_order whether the selective predicate exists or not.
Therefore, the cost is mostly against the full table scan on the Employee table and check each row with purchase_orders. Let’s rewrite the same result by using IN clause as proposed by the oracle (QUERY-2).
Query-2
--
SELECT e.*
FROM employee e
WHERE e.employee_id IN (SELECT p.person_id /* Person who created the order is employee */
FROM purchase_orders p
WHERE p.customer_id = 99); /* Selective Predicate customer_id=99 */
--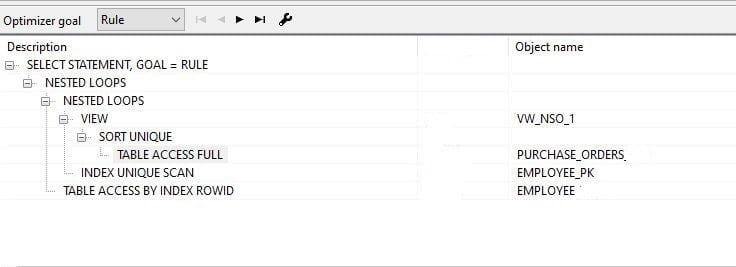
Following explain plan is more beneficial because of cost is low compared to the earlier plan. According to the plan, there is a full table scan on purchase_order first, and after that index scan for the Employee table. This is a good plan to execute because of returning fewer rows by subquery and needing to fetch less no of rows from Employee table using index.
Also, I want to note one piece of information here. Subquery converts into view by query optimizer then join view and parent query using employee_id which is an index of the Employee table. Also, customer_id is an index of the purchase_orders table therefore fetch person_id using Index.
Use EXISTS – Selective Filter in the Parent Query
In this case, I’m going to explain how Exists is beneficial when the selective filter in the parent query. We can use both IN and EXISTS clauses to fetch the same results but those two have different performances. Let’s try with IN clause first and let’s move to EXISTS second. I want to filter Employee who works as a manager and works in the manufacturing department but who need to already post a purchase order. That means we need to add a selective predicate in our query here.
Query-3
--
SELECT e.*
FROM employee e
WHERE e.department_id = 'Manufacturing' /* first selective predicate */
AND e.job_title = 'Manager' /* second selective predicate */
AND e.employee_id IN (SELECT p.person_id FROM purchase_orders p);
--
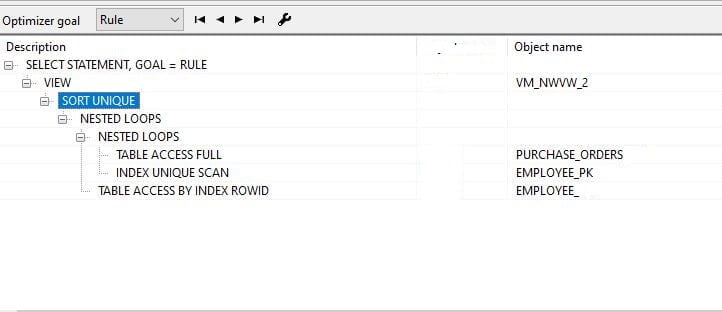
I like to explain this a bit further about this explain plain then you can realize how the query optimizer works in this type of situation.But how it return employee_ids?
According to the explain plan first, run a full table scan to the purchase_orders and then sort selective records into an order. Why is sorting? it’s because of purchase_orders table returns only unique employee_ids but in this case, the selective list is large. it’s because there is no selective predicate(this example may have fewer selective predicates) in the subquery. Therefore, it took time to this plan.
Now you can realize earlier case use of IN clause and this use of IN clause shows the same explain plan, but the cost is different. It’s because of the below reasons.
- Where to use selective predicate
- Returning dataset by a subquery.
- How indexes are used when running a query by the Query optimizer.
Now rewrite the query using EXISTS. Here now you know to start from an outer query and when executing check whether any matching row exists with the subquery.
Query-4
--
SELECT e.*
FROM employee e
WHERE e.department_id = 'Manufacturing' /* first selective predicate */
AND e.job_title = 'Manager' /* second selective predicate */
AND EXISTS (SELECT 1
FROM purchase_orders p
WHERE e.employee_id = p.person_id);
--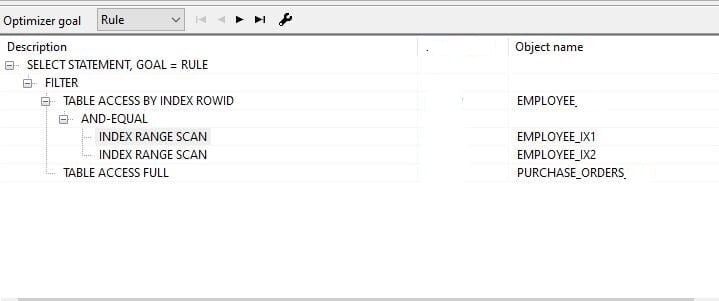
Now you know how cost reduces in this case. The employee table goes through the indexes and filters out the employee rows and matches those rows with the purchase_orders table to filter out the rest. The employee table returns fewer datasets and therefore needs to match a few with the purchase_orders table.
Here we have used two different indexes for department_id and the job_title. therefore, go through the index range for each attribute. If we can go for a concatenated index for employee_id, and job_title then just one index range scan to filter out the Employee table. That will improve some performance as well.
Cost Base Oracle optimizer
As I mentioned above there is no change between the explain-plan when generating explain plan by cost base optimizer. All almost every case it generates the same explain-plan whether the use of IN or EXISTS in subqueries. First, I run Query-1 and Query-2 for most selective predicates in a subquery. You can see both Query-1 and Query-2 are generating the same explain plan.
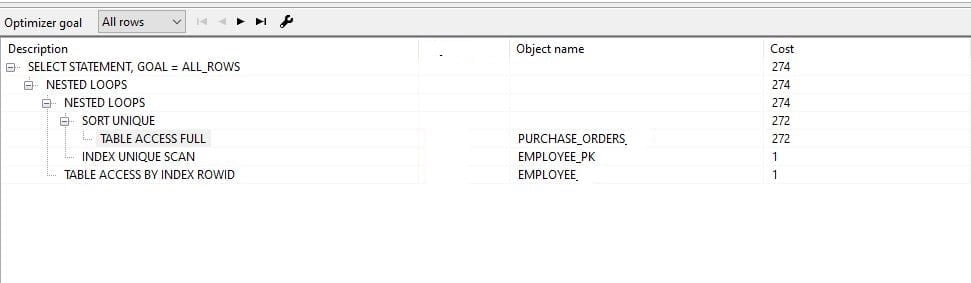
Next, I run a cost base optimizer explain-plan for Query-3 and Query-4. Those queries with the most selective predicates are in the outer query. That means fewer records will return from the outer query. But still, you can see both explain plans are the same for Query-3 and Query-4.
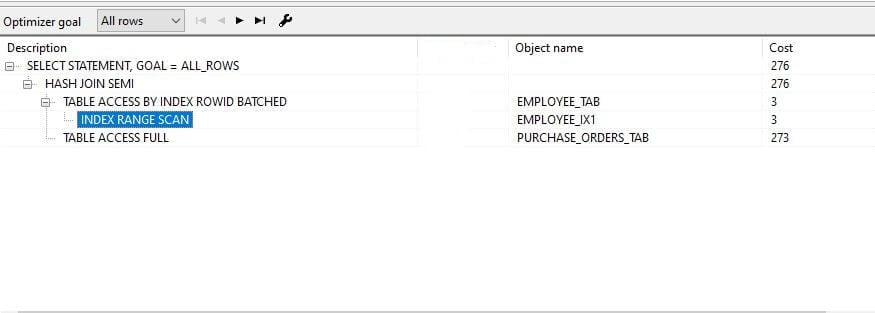
Cost base optimizer generates Explain plains based on data load in the database. Therefore it does not generate the same explain plan every time with your cases. But it generates the same explain plan for IN and EXISTS(exists vs in) clauses with the same data load.
Now you know IN and Exists both are good but need to use them in the best place. Again, the same theories do not work everywhere therefore you have to analyze the dataset, execution plan, and query running time when improving the performance. This is general guidance for how to apply IN and EXISTS(exists vs in) clauses according to the situation.
Summary
I would like to summarize the general guidance I explain here. Here we discussed how to use IN versus Exists in inner queries. Query optimizer runs different ways with IN and Exists.
If you have a selective predicate and returning a few records in a subquery better to use the IN clause for subqueries. Also, there are selective predicates, and few records return from the parent query then use EXISTS for the subquery.
You may Like

All SQL Related posts https://ennicode.com/category/sql/
Reference
Oracle Doc: https://docs.oracle.com/cd/B12037_01/server.101/b10752/sql_1016.htm
Burleson Consulting: https://www.dba-oracle.com/t_exists_clause_vs_in_clause.htm
